
实验报告
报告标题:Spark
学号:20190423
姓名:金玉洲
日期:2022-12-21
一、实验环境
- 操作系统:
windows10
centos7
- 相关软件(含版本号):
hadoop-2.6.0-cdh5.7.0
spark-2.4.6-bin-hadoop2.6
- 其它工具:
Vmware WorkStation 16 Pro
FinalShell 1.0.0.0
IntelliJ IDEA 2022.1
二、实验内容及其完成情况
(针对上述实验内容逐一详述实验过程)
- Spark 环境搭建:
解压缩spark
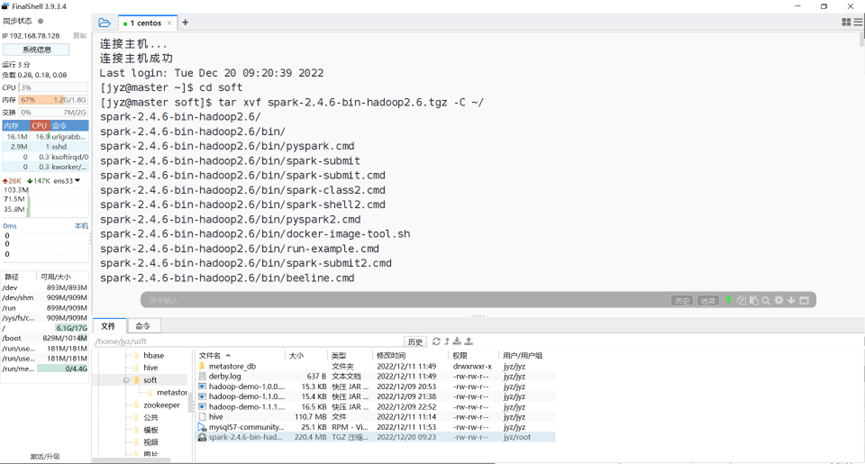
图表 1 解压缩spark
改名
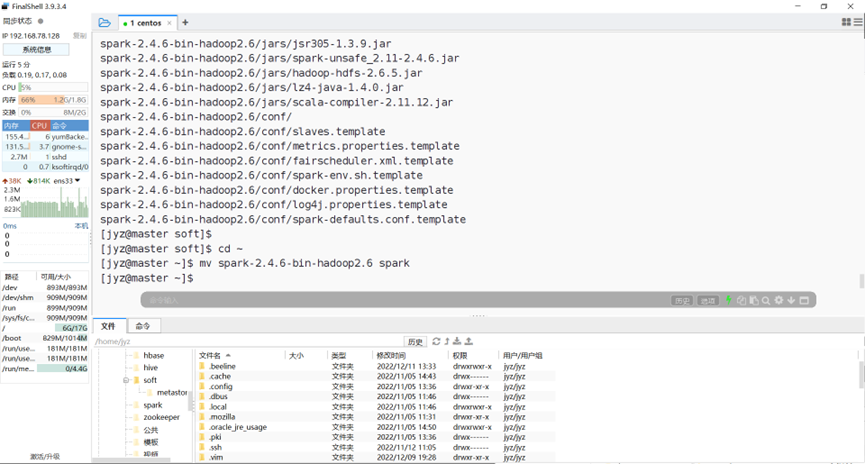
图表 2 改名
配置spark环境变量
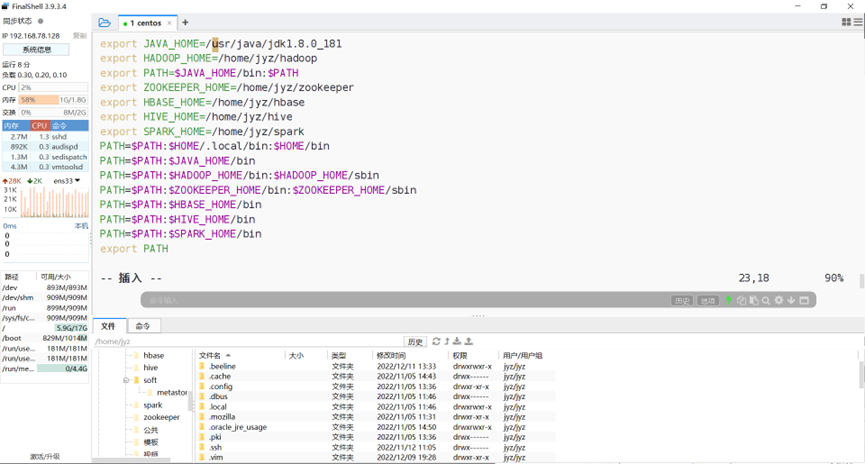
图表 3 配置spark环境变量
拷贝spark-env.template,并修改
图表 4 拷贝spark-env.template,并修改
启动spark-shell
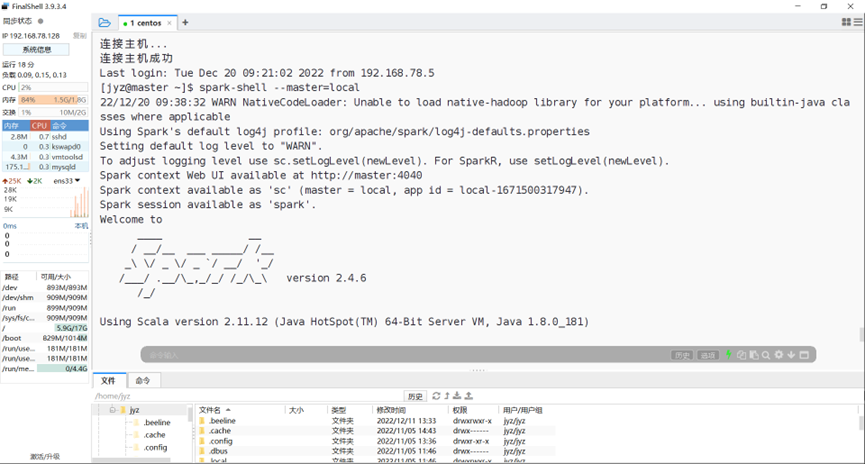
图表 5 启动spark-shell
拷贝slaves.templates
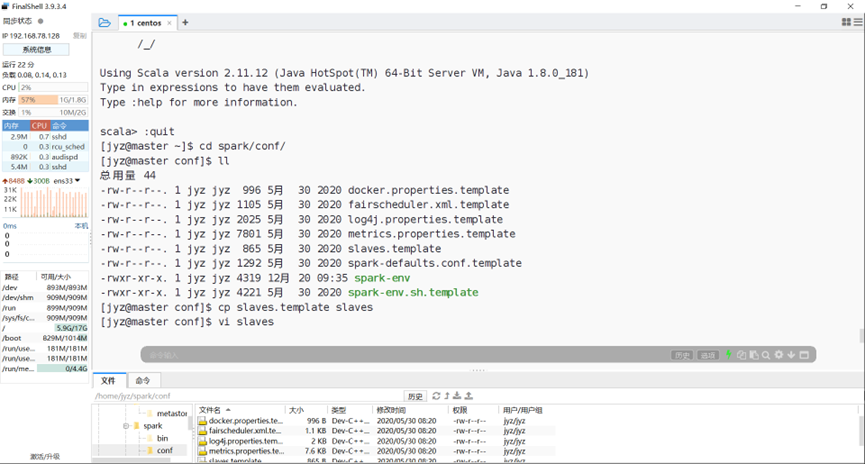
图表 6 拷贝slaves.templates
配置slaves
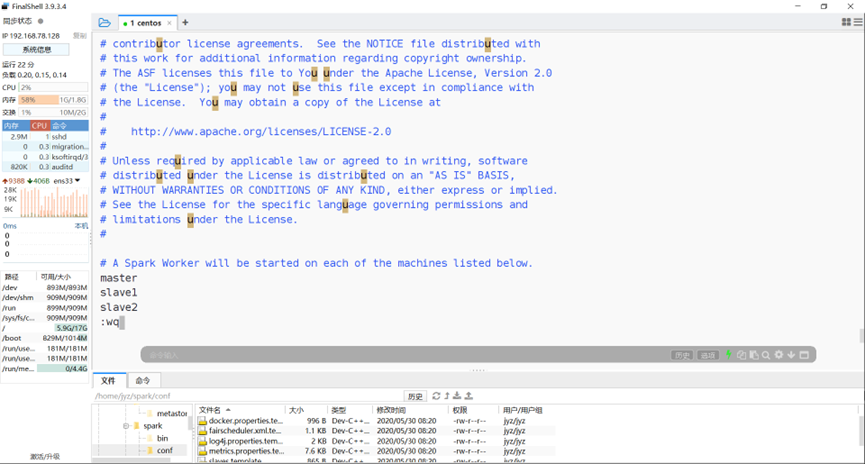
图表 7 配置slaves
拷贝spark到其他虚拟机
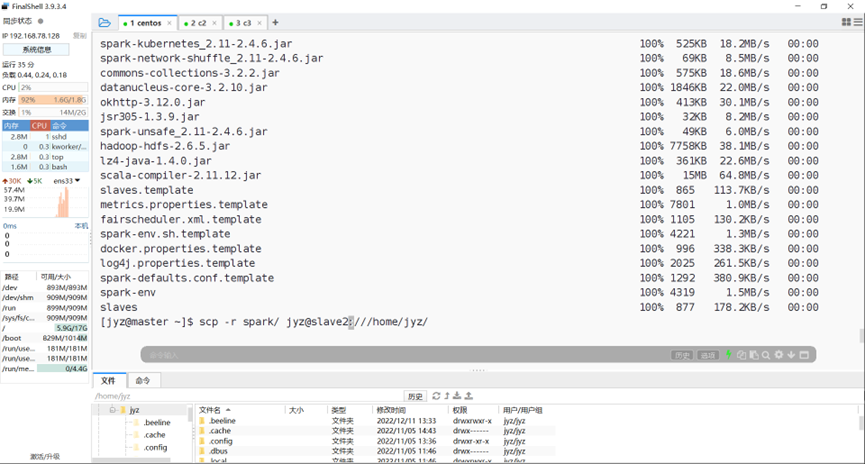
图表 8 拷贝spark到其他虚拟机
修改slave1的spark-env
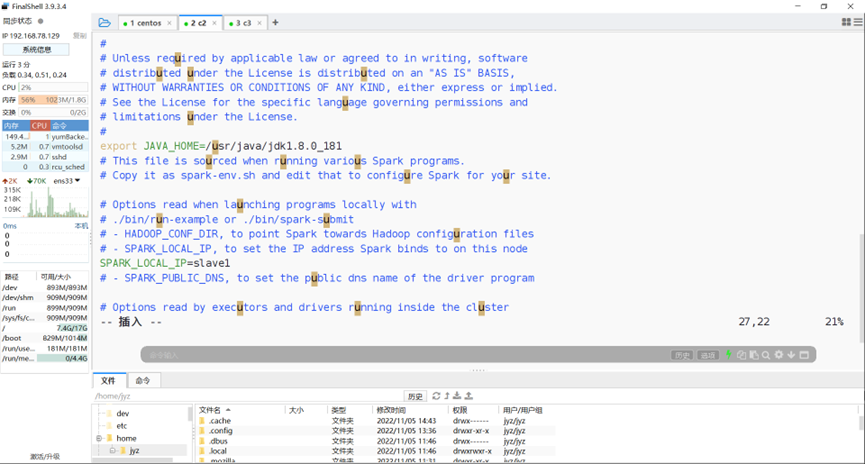
图表 9 修改slave1的spark-env
修改slave2的spark-env
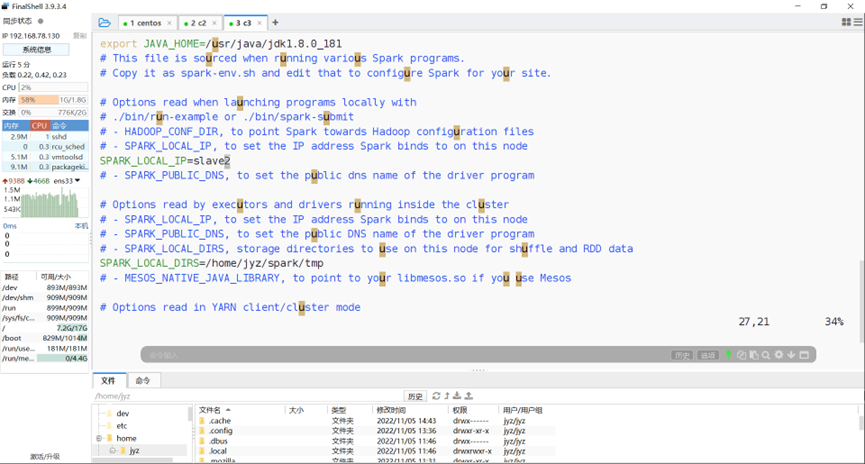
图表 10 修改slave2的spark-env
启动start-all
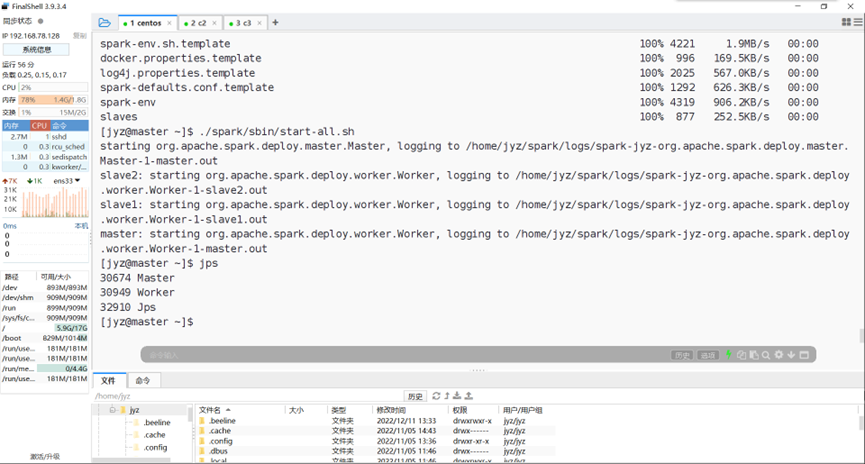
图表 11 启动start-all
Slave1的jps
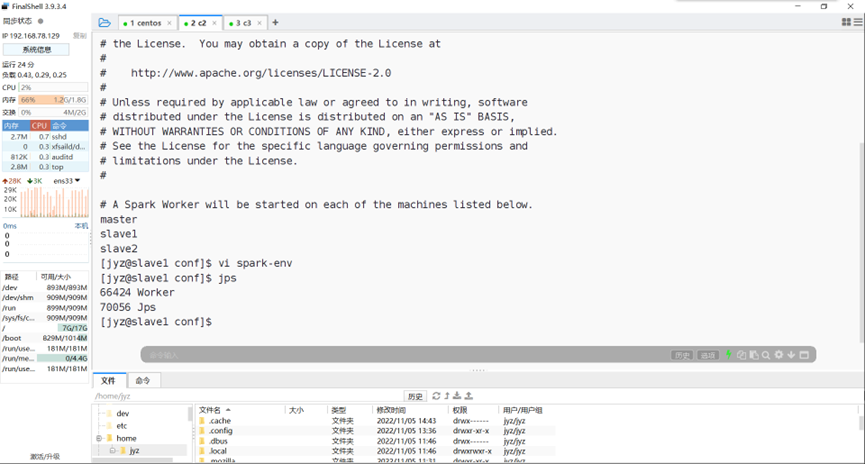
图表 12 Slave1的jps
Slave2的jps
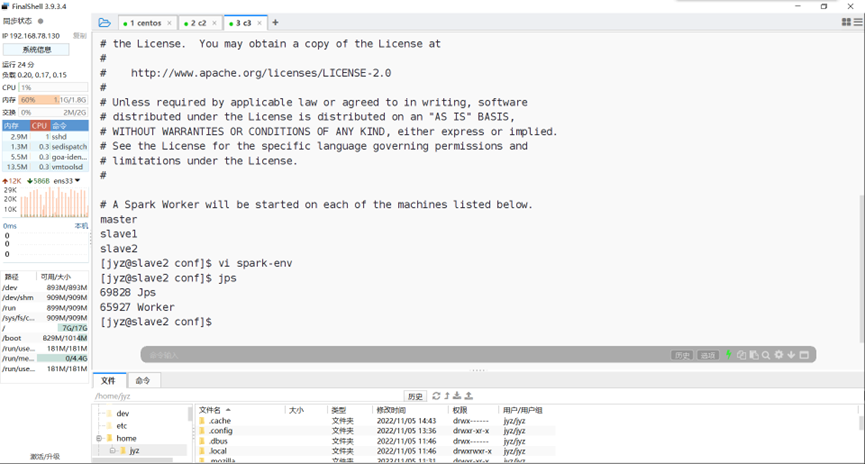
图表 13 Slave2的jps
查看8080
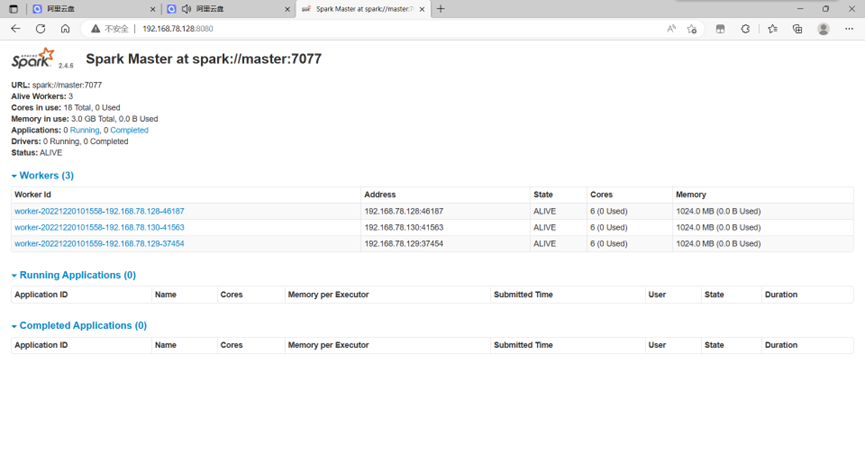
图表 14 查看8080
启动spark-shell
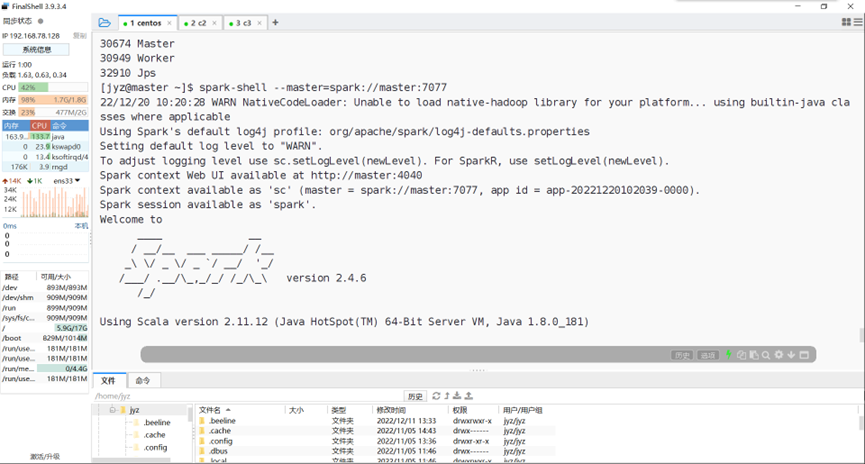
图表 15 启动spark-shell
运行计算圆周率的示例,Pi is roughly 3.1455757278786396
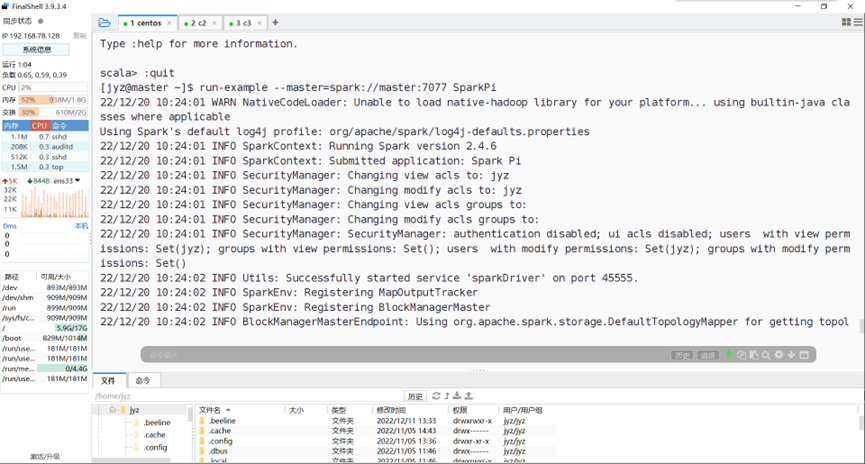
图表 16 运行计算圆周率的示例,Pi is roughly 3.1455757278786396
8080端口查看
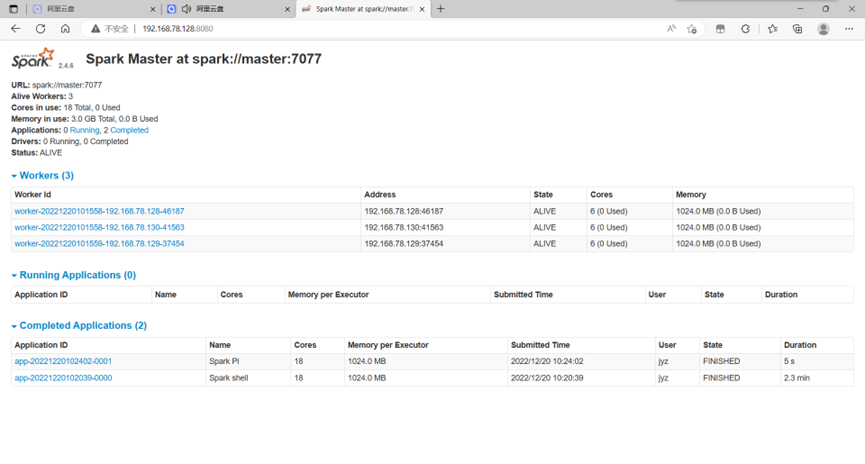
图表 17 8080端口查看
- Scala 练习题
MyPiUtil代码:
1 | object MyPiUtil{ |
IDEA中不给参数时的运行结果
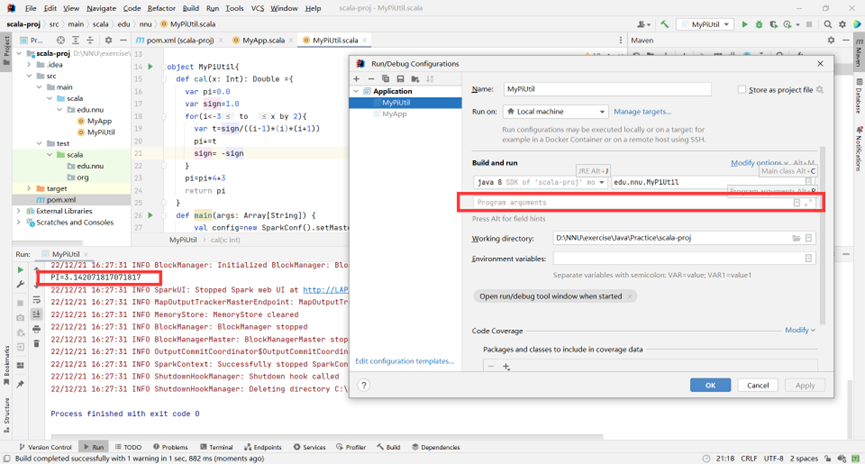
图表 18 不给参数时的运行结果
IDEA中参数为21时的运行结果

图表 19 IDEA中参数为21时的运行结果
在虚拟机中运行,不给参数
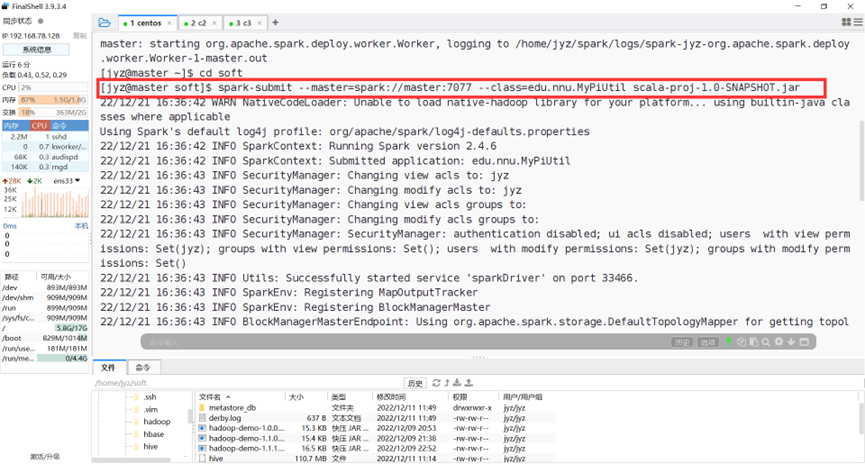
图表 20 在虚拟机中运行,不给参数
不给出参数的运行结果
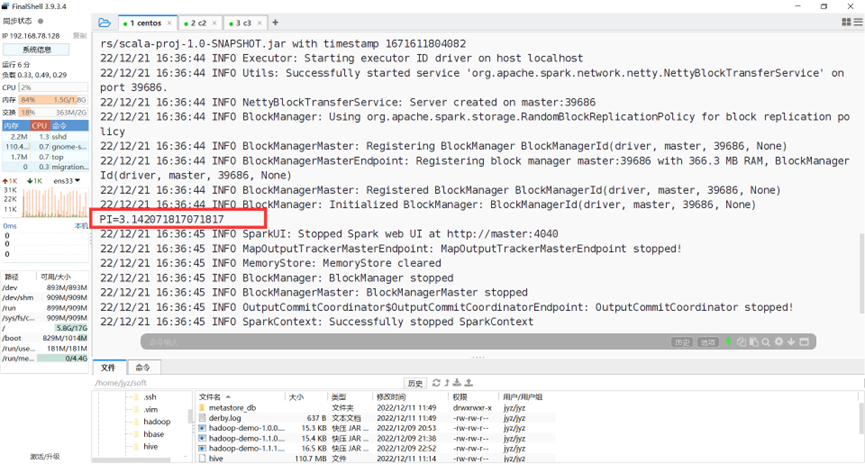
图表 21 不给出参数的运行结果
给出参数为21
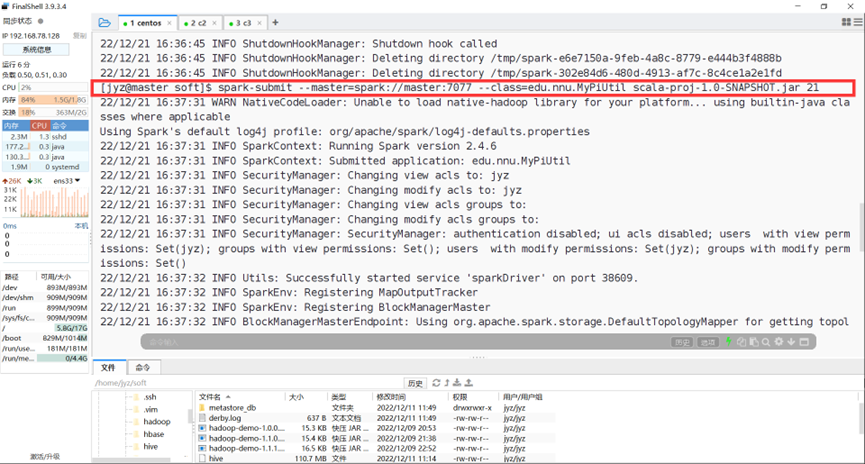
图表 22 给出参数为21
参数为21的运行结果
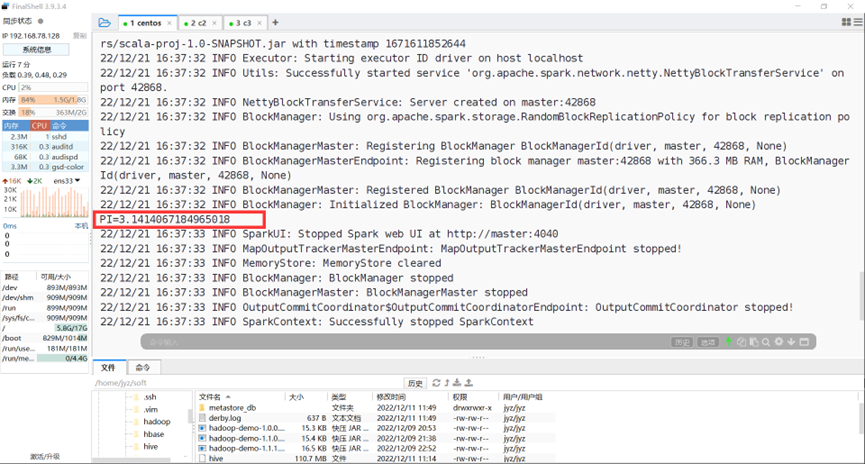
图表 23 参数为21的运行结果
- Spark练习题
上传数据文件
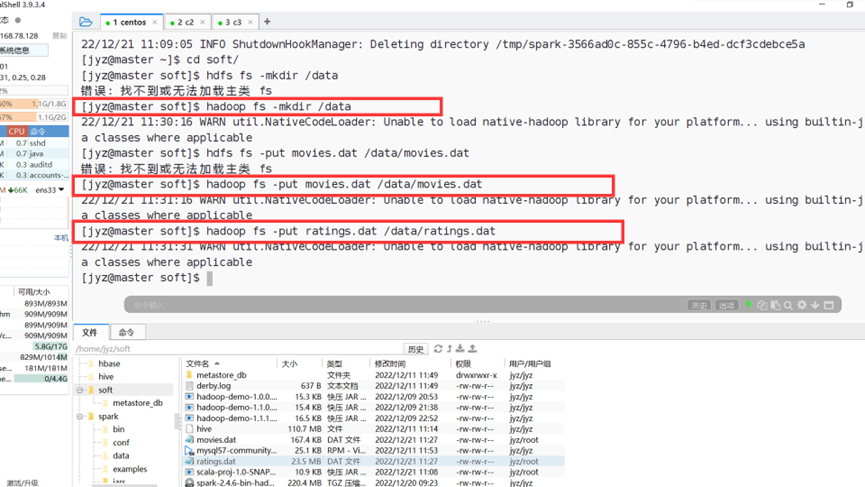
图表 24 上传数据文件
在浏览器查看上传的数据文件
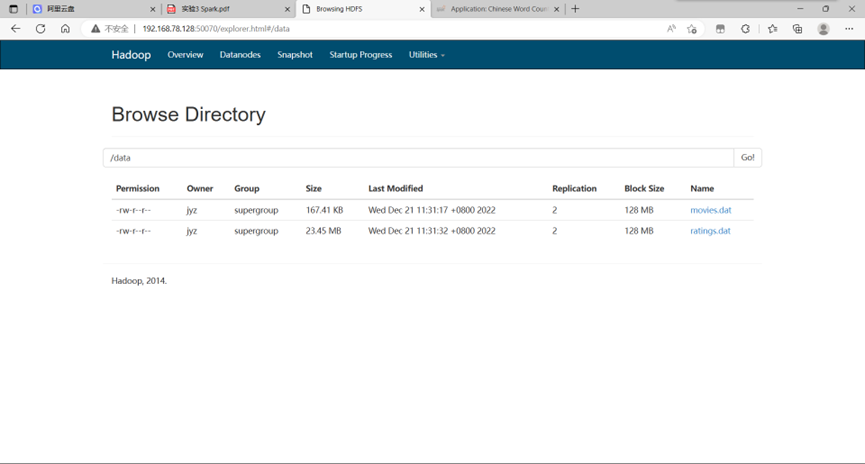
图表 25 在浏览器查看上传的数据文件
Spark中导入数据movies.dat
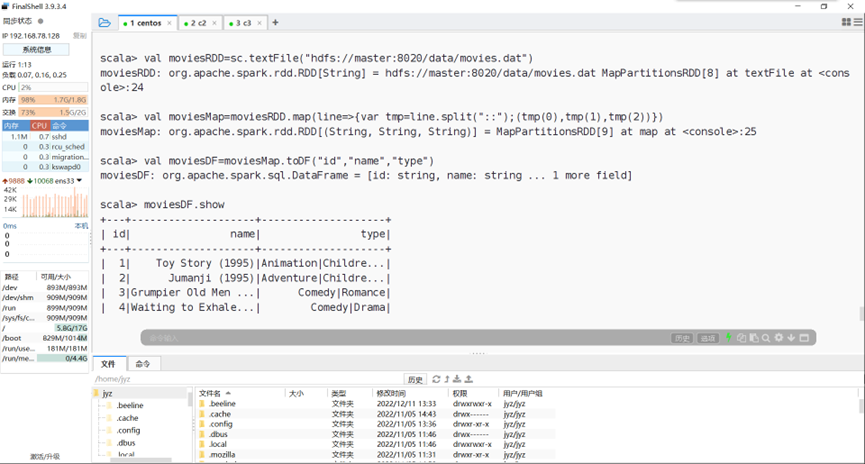
图表 26 Spark中导入数据movies.dat
查看导入movies.dat结果
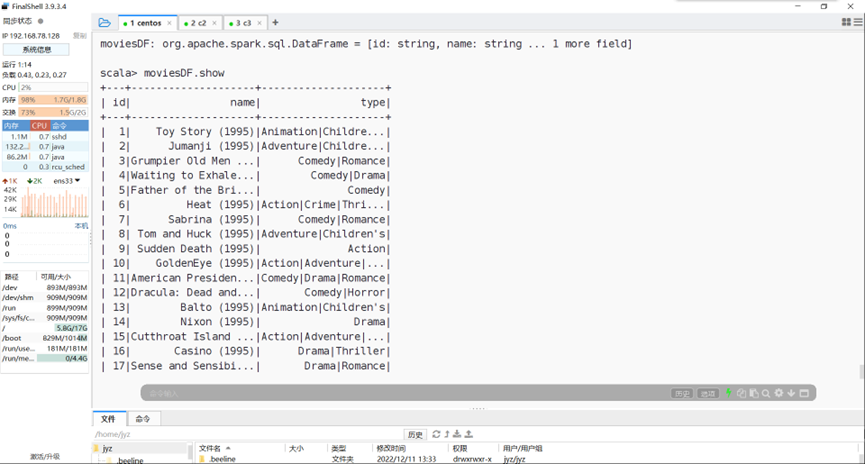
图表 27 查看导入movies.dat结果
导入ratings数据
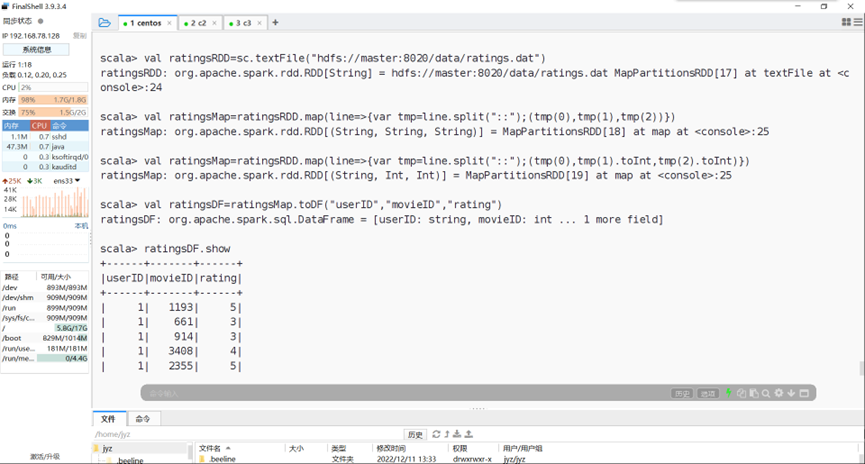
图表 28 导入ratings数据
查看ratings导入结果
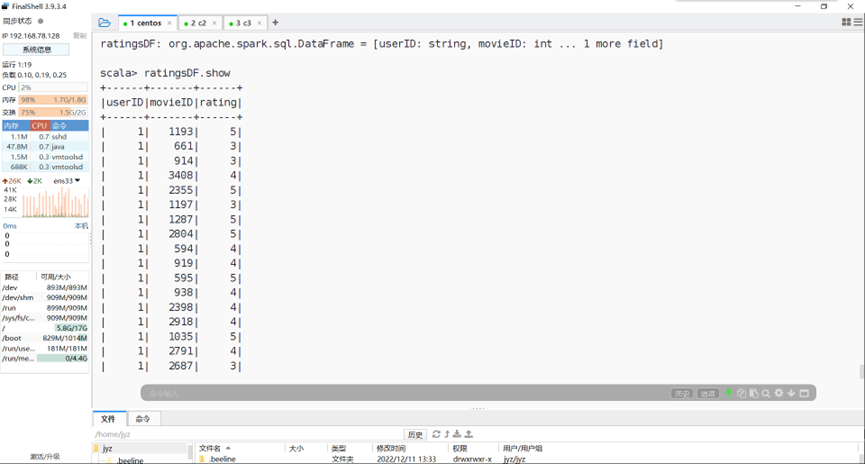
图表 29 查看ratings导入结果
建立两张临时表
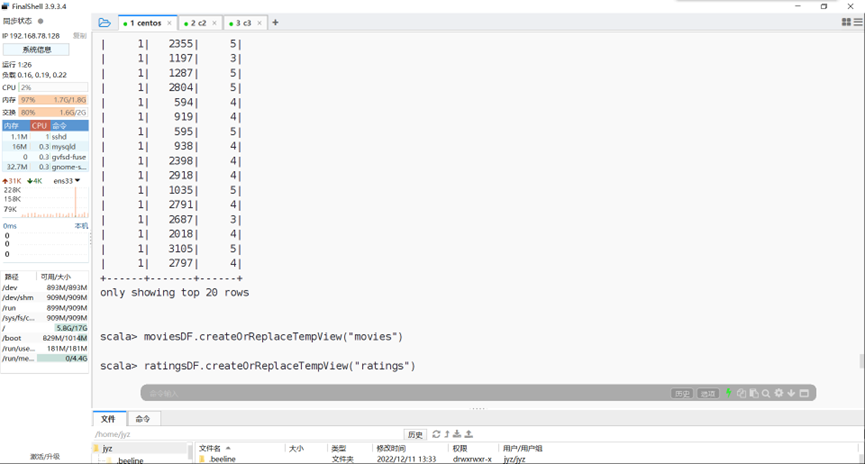
图表 30 建立两张临时表
Sql语句以及运行结果
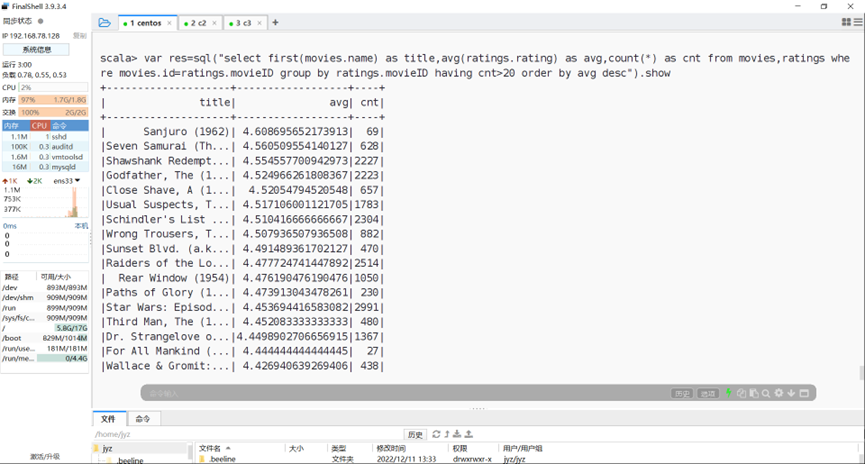
图表 31 Sql语句以及运行结果
三、实验总结
在编写spark sql语句时,如果进行多表联查,需要在查询的字段前用first()包裹起来,否则就会报错,在sql语句编写多表联查的时候对于语句不熟悉,查看了许多网上的资料才最终写出来。
IDEA中加载scala依赖包之前一直有问题,运行报:Error:scalac: No ‘scala-library*.jar’ in Scala compiler classpath in Scala SDK scala-sdk-2.11.12错误,后来是将library中的scalaSDK重新选择后才成功运行。
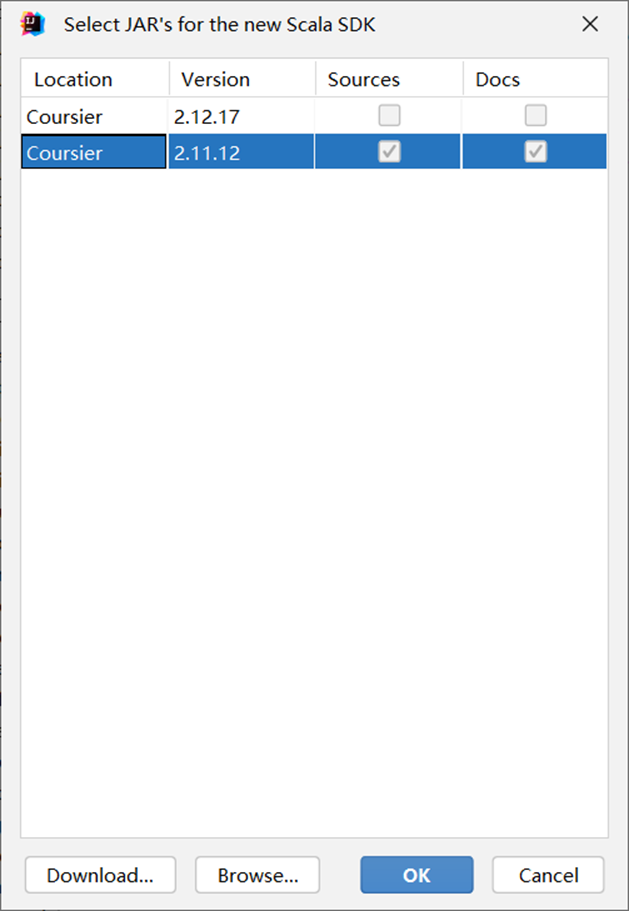
图表 32 选择sdk