
考核说明
总成绩构成:
出勤 (10%)+ 课节作业 (50%) + 项目大作业 (40%)
项目大作业
考核要求:
选定一个适用机器学习技术来解决的现实问题,运用所学的机器学习手段及方法构建一个完整的项目。要包含完整的机器学习要素:任务介绍及机器学习术语描述,数据集中的样本及标签解读,模型设计原理,损失函数设计,优化方法,代码实现,实验结果及分析。
呈现形式:
- 书面报告:在本文档中完成,直接提交 notebook 电子文件到 AIstudio 云平台上,项目内容解读使用 Markdown 模块, 项目代码使用 Code 模块,以及代码模块的运行结果
- 现场讲解及答辩。
评分标准:
将按照考核要求中的要素的完整性进行评分,主要评估机器学习要素解读的正确性,完整性,以及项目解决方案设计的启发性。评分详细条目及分值分配如下表所示:
| 任务介绍 (5 分) | 数据集描述 (5 分) | 模型分析 (20 分) | 损失函数分析 (10 分) | 优化方法 (5 分) |
|---|---|---|---|---|
| 得分 | 得分 | 得分 | 得分 | 得分 |
| 代码实现 (30 分) | 实验结果及分析 (10 分) | 现场讲解及答辩 (15 分) |
|---|---|---|
| 得分 | 得分 | 得分 |
注意
- 提交大作业时,同时上传查重报告,以避免抄袭。
- 不允许贴图文本块以及公式块,务必手工录入。
1.任务介绍
去年我的母亲想要把一张手写的合同录入到电脑中打印下来,但是她并不会使用电脑,因此就找到了我,我的第一想法就是qq自带的图片识别文字的功能,但是由于手写的实在是有点乱,识别的效果并不好,最终还是手打了一份。如今,我想通过机器学习的SVM模型去尝试着实现手写汉字识别,并尽可能达到一个好的效果。
本次大作业中,我先后尝试了SVM与KNN两种方法对手写汉字进行识别,并尝试通过PCA降维提高准确率。
2.数据集描述
- 中科院自动化研究所-手写中文数据集
- 数据来源:http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html
- 包含在线和离线两类手写数据,HWDB1.0
1.2总共有3895135个手写单字样本,分属7356类(7185个汉字和171个英文字母、数字、符号);HWDB2.02.2总共有5091页图像,分割为52230个文本行和1349414个文字。所有文字和文本样本均存为灰度图像。 - 使用建议:数据为单字,白色背景,可以大量合成文字行进行训练。白色背景可以处理成透明状态,方便添加各种背景。对于需要语义的情况,建议从真实语料出发,抽取单字组成文字行
3.模型分析
3.1 主要思想
SVM模型的主要采用最大化最小几何间隔的思想,即尽力让边界附近的样本不仅保持在各自应属的一边,并且距离边界越远越好。SVM的学习目标就是找到一个决策超平面,使得训练样本集到超平面的最小距离最大化。
3.2 SVM方法
3.2.1 硬间隔SVM
当训练样本线性可分时,可以直接通过硬间隔最大化学习一个线性可分支持向量机。但是当特征维度很大时,这种方式计算效率低,耗费内存大。为了求解线性可分支持向量机的最优化问题,将它作为原始最优化问题,应用拉格朗日对偶性,通过求解对偶问题(dual problem)得到原始问题(primal problem)的最优解。
3.2.2 软间隔SVM
对于决策边界近似线性的数据,可以使用软间隔的方法,允许数据跨越决策面(允许误分类),但是需要对跨越决策面的数据加以惩罚。对于复杂决策面的数据,则通过核函数的方法将低维数据映射到高维甚至无限维空间,将低维线性不可分的数据转换成高维线性可分的数据,进而化简决策问题。
3.2.3 核函数与核方法
对于线性不可分的数据,可以引入核函数。核方法的基本原理是把原坐标系里线性不可分的数据使用核函数(Kernel)投影到另一个空间,尽量使得数据在新的空间里线性可分。核函数方法的广泛应用, 有以下特点或用途:
- 核函数的引入避免了“维数灾难”,大大减小了计算量。而输入空间的维数n对核函数矩阵无影响,因此,核函数方法可以有效处理高维输入。
- 无需知道非线性变换函数的形式和参数。
- 核函数的形式和参数的变化会隐式改变从输入空间到特征空间的映射,进而对特征空间的性质产生影响,最终改变各种核函数方法的性能。
- 核函数方法可以和不同的算法相结合,形成多种不同的基于核函数技术的方法,且这两部分的设计可以单独进行,并可以为不同的应用选择不同的核函数和算法。
3.3 项目分析
KNN主要适用于准确度要求不那么高,样本较少的情况。SVM适用于对正确率有着比较高的要求,样本比较多的情况。并且KNN不能处理样本维度太高的东西,SVM处理高纬度的数据比较优秀。对于手写汉字识别这个目标来说,汉字有很多很多,并且对于识别的正确率也有着很高的要求,因此KNN就不适用了,选择SVM模型。并且由于汉字图片线性不可分,因此需要使用核函数,这里选择了高斯核函数(Gaussian Kernel),在SVM中也称为径向基核函数(Radial Basis Function,RBF),它是非线性分类SVM最主流的核函数。
同时在图片预处理中,也可以使用PCA降维的方法来提取主要特征,尝试是否能提高准确率。最后也可以使用KNN做一个对比。
4 损失函数分析
SVM的损失函数为Hinge loss,对此共有两种解读观点。
4.1 第一种解读观点
优化目标中关注的是变量ξ的最小值,从变量ξ的角度来审视一下两个约束条件,可以描述为
$\xi_i\ge1-y_i(w^T+b),i=1,2,…,N$
$\xi_i\ge0,i=1,2,…,N$
可以看出,这两个不等式同时约束了松弛变量ξ的下界,因此,要求这两个约束不等式约束条件下的ξ的最小值,则只需要最小化下界中的较大的下界即可,即为:
$min max{0,1-y_i(w^Tx_i+b)}$
所以软支持向量的优化问题可以描述为:$min[\frac 12w^Tw+\sum_{i=1}^Nmax{0,1-y_i(w^Tx_i+b)}]$
所以损失函数为$max{0,1-y_i(w^Yx_i+b)}$,第一项可以看作是模型参数的$L_2$范数正则化项。
4.2 第二种解读观点
直接令$\xi_i=max{0,1-y_i(w^Tx_i+b)}$则,可以看出$\xi_i\ge0$,所以软支持向量机优化问题中的第二个约束条件恒成立。当$1-y_i(w^Tx_i+b)>0$时,则$max{0,1-y_i(w^Tx_i+b)}=1-y_i(w^Tx_i+b)\equiv\xi_i$,即$y_i(w^Tx_i+b)=1-\xi_i$
当$1-y_i(w^Tx_i+b)\le0$,则$max{0,1-y_i(w^Tx_i+b)}=0\equiv\xi_i$,即$\xi_i=0$,所以$1-y_i(w^Tx_i+b)\le\xi_i$,即$y_i(w^Tx_i+b)\ge1-\xi_i$
综合上述两种情况,软支持向量机优化问题中的第一个约束条件恒成立。因此软支持向量的优化问题可以描述为如下无约束优化问题(这也是SVM的另一种新的形式化描述,侧重于体现损失函数,但不具有优化求解的便利性):$min[\frac 12w^Tw+\sum_{i=1}^Nmax{0,1-y_i(w^Tx_i+b)}]$
所以,损失函数为$max{0,1-y_i(w^Tx_i+b)}$,第一项可以看做是模型参数的$L_2$范数正则化项。该损失函数在业界内有一个名字,即所谓的铰链损失。
5 优化方法
5.1 SMO算法
基本思想:如果所有$\alpha$(每一个样本都对应着一个$\alpha$)都满足最优化问题的KKT条件,那么这个最优化问题的解就得到了。
SMO算法尝试将原始的二次规划问题分解为一个个小的二次规划问题。SMO算法首先选择两个违背KKT条件最严重的α,并固定其它α,针对这两个α构造一个二次规划问题,重复该过程,直到所有的α都满足KKT条件。这样得到的解就更接近原始的二次规划问题的解。具体地,SMO算法在初始化所有的变量αi,i=1,2,…,n之后,不断执行下述三个步骤,直到收敛:
- 根据一定的启发式策略(如预测误差的差值最大的两个样本对应的α),选取两个优化变量αi和αj
- 将其他的变量当做常数,求解只有αi和αj两个变量的最优化问题 3、更新αi和αj,如果变量收敛,则停止;否则,重复步骤1
由SMO算法可得出所有α值,如何根据对偶问题的解α反推原问题的解w和b?
首先,根据前述拉格朗日函数对w偏导公式,可知$w=\sum_{i}\alpha_iy_ix_i$。
那么如何求b呢?此处需要用到KKT条件。根据KKT条件,原问题的最优解w⋆满足下述条件
$\alpha^*_i\ge0$
$y_i(w^{T}x_i+b^)\ge1$
$\alpha^*_i(y_i(w^{T}x_i+b^)-1)=0$
5.2 对偶问题
构建拉格朗日法将原问题转换成无约束的最优化问题,拉格朗日函数(w,b)可以写成:$L(w,b,\alpha)=\frac 12||w||^2-\sum_{i}\alpha_i(y_i(w^Tx_i+b)-1)$
现在我们的问题为:$min_{w,b}max_{\alpha_i\ge0}L(w,b,\alpha)$,由于问题时凸二次规划问题,且满足Slater条件,因此上述问题等价于$max_{\alpha_i\ge0}min_{w,b}L(w,b,\alpha)$
当原问题转化为对偶问题之后,想要原问题的解与对偶问题的解等价,即通过求对偶问题的解可以得到原问题的解,则需要满足KKT条件。首先,需要满足KKT条件的第一个条件。求解内部的最小化问题,将拉格朗日函数分别对w和b求偏导,并令偏导为零,有:
$\frac{\partial L(w,b,\alpha)}{\partial w}=w-\sum_{i}\alpha_iy_ix_i=0\Rightarrow w=\sum_{i}\alpha_iy_ix_i$
$\frac{\partial L(w,b,\alpha)}{\partial b}=-\sum_{i}\alpha_iy_i=0\Rightarrow \sum_{i}\alpha_iy_i=0$
将$w=\sum_{i}\alpha_iy_ix_i$代入拉格朗日函数,则我们的优化目标等价于$L(w,b,\alpha)=\sum_{i}\alpha_i-\frac 12\sum_{i}\sum_{j}\alpha_i\alpha_j y_i y_j(x^T_ix_j)$
此时,我们的最优化问题等价于
$max_{\alpha_i\ge0}\sum_{i}\alpha_i-\frac 12\sum_{i}\sum_{j}\alpha_i\alpha_j y_i y_j(x^T_ix_j)$
s.t.$\sum_{i}\alpha_iy_i=0$
6.代码实现
6.1 解压缩数据集并读入数据标签
1 | # 导入模块 |
['00000', '00001', '00002', '00003', '00004', '00005', '00006', '00007', '00008', '00009']
['一', '丁', '七', '万', '丈', '三', '上', '下', '不', '与']
6.2 读取手写汉字图片数据
1 | #二维列表,[手写汉字的图片信息,汉字的编号] |
6.3 使用PCA,观察不同维度下的方差占比
1 | from sklearn.decomposition import PCA |
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:22: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/font_manager.py:1331: UserWarning: findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans
(prop.get_family(), self.defaultFamily[fontext]))
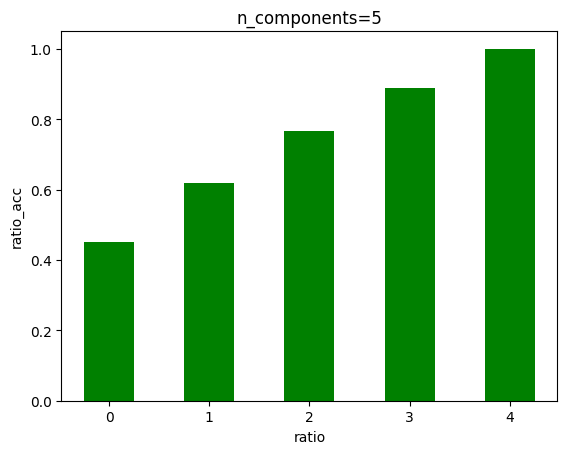

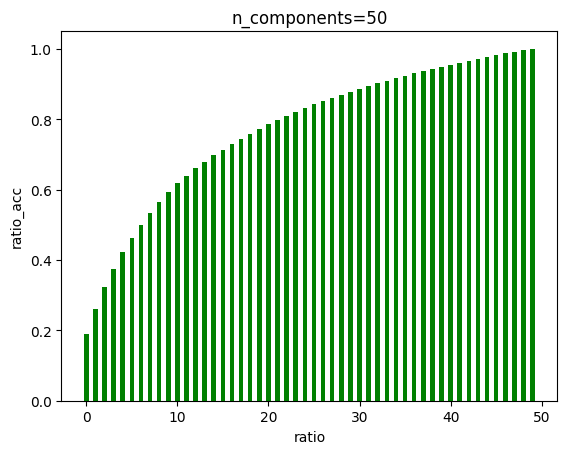
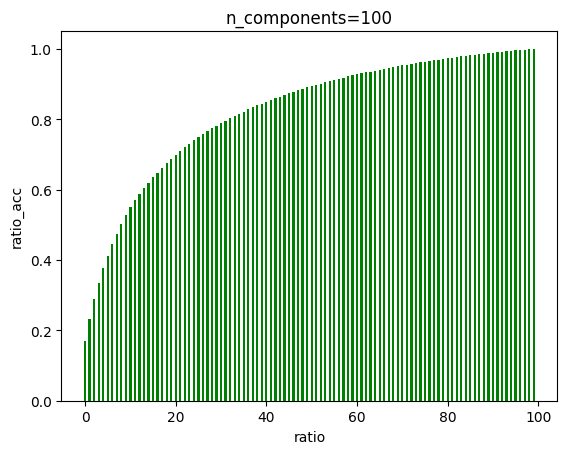
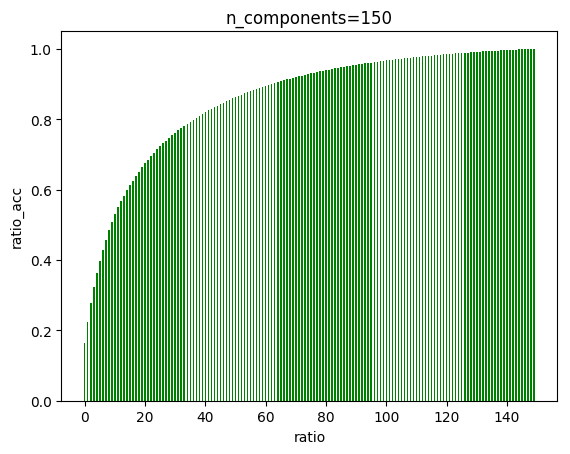
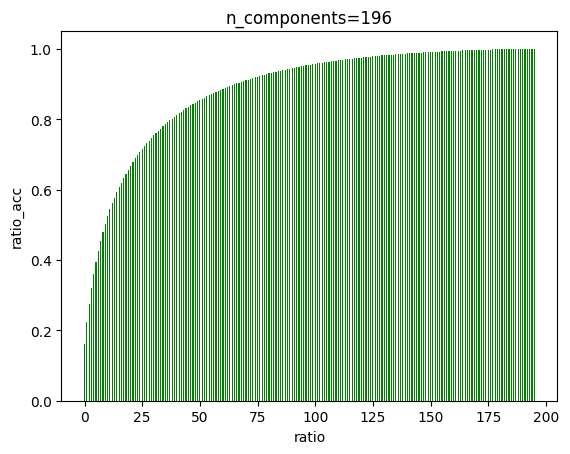
6.4 由PCA降维图可以看出,在大概135左右,曲线趋近于一条直线,我们可以降维至135
1 | import numpy.linalg as LA |
残差的Frobenius范数:
220.32679427894584
重建误差:残差的Frobenius范数的平方:
48543.89627723692
6.5 使用原始数据进行训练测试
1 | #二维列表,[手写汉字的图片信息,汉字的编号] |
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:19: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
训练数据格式:(1984, 196)
测试数据格式:(397, 196)
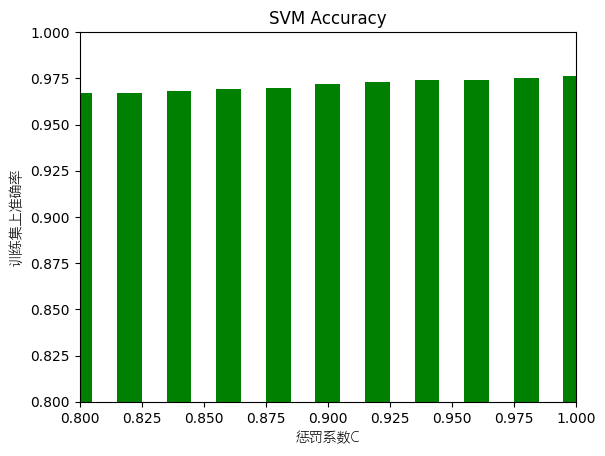
[0.967, 0.967, 0.968, 0.969, 0.97, 0.972, 0.973, 0.974, 0.974, 0.975, 0.976]
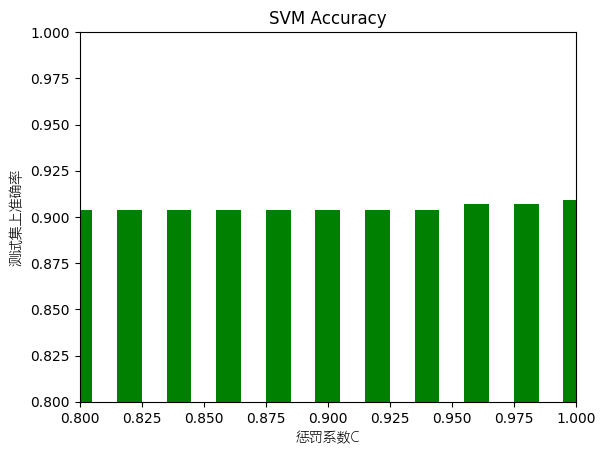
[0.904, 0.904, 0.904, 0.904, 0.904, 0.904, 0.904, 0.904, 0.907, 0.907, 0.909]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/font_manager.py:1331: UserWarning: findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans
(prop.get_family(), self.defaultFamily[fontext]))
['./svm.pkl']
6.6 使用降维重建后的数据进行训练测试
1 | import numpy.linalg as LA |
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:19: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:58: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
训练数据格式:(1984, 196)
测试数据格式:(397, 196)
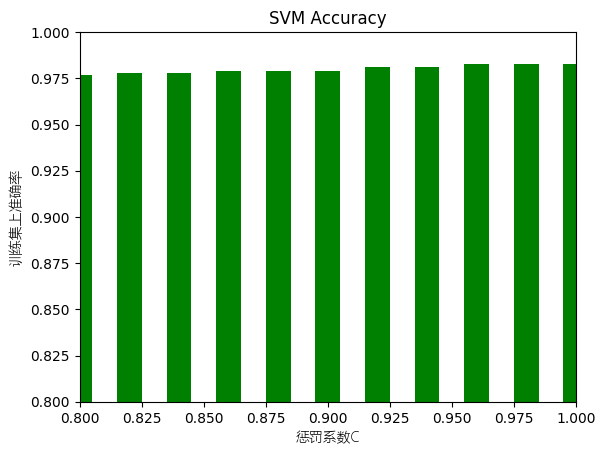
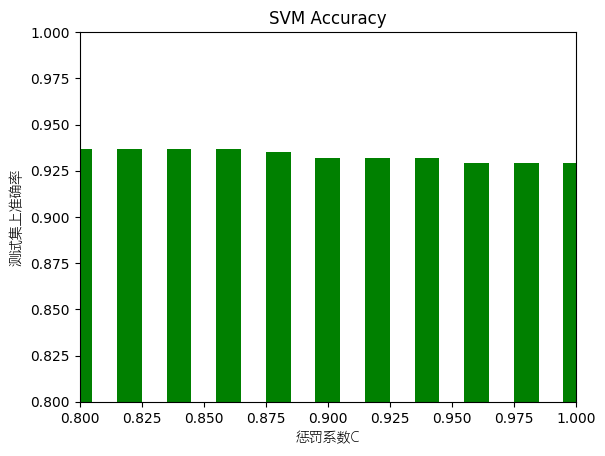
[0.977, 0.978, 0.978, 0.979, 0.979, 0.979, 0.981, 0.981, 0.983, 0.983, 0.983]
[0.937, 0.937, 0.937, 0.937, 0.935, 0.932, 0.932, 0.932, 0.929, 0.929, 0.929]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/font_manager.py:1331: UserWarning: findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans
(prop.get_family(), self.defaultFamily[fontext]))
['./svm_pca.pkl']
6.7 混淆矩阵
1 | from sklearn import svm |
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:25: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/font_manager.py:1331: UserWarning: findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans
(prop.get_family(), self.defaultFamily[fontext]))

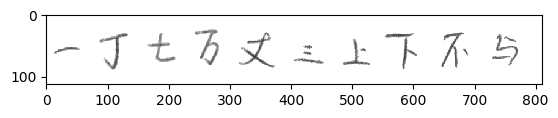
6.7 对包含一段话的图片进行字符切割,并预测这段话是什么
1 | import numpy as np |
split/origin/TV~{G4`PBZ[1_(FLC76[}12.png
26 90
13 56
87 134
165 212
243 283
314 375
406 454
485 530
555 607
646 691
730 772
预测结果
['不', '丁', '丈', '万', '丈', '丈', '上', '下', '不', '与']
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/font_manager.py:1331: UserWarning: findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans
(prop.get_family(), self.defaultFamily[fontext]))
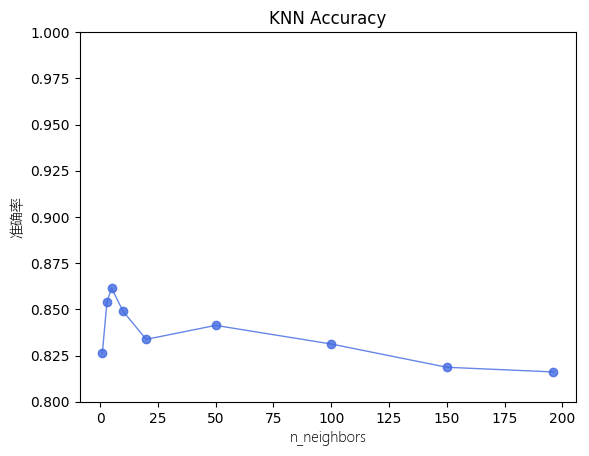
6.8 KNN模型效果测试
1 | from sklearn.neighbors import KNeighborsClassifier |
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/font_manager.py:1331: UserWarning: findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans
(prop.get_family(), self.defaultFamily[fontext]))
7.实验结果分析
关于pca降维,虽然135维能保留绝大部分特征,但是后面的曲线增长曲线其实并不算很小,因此降维后的准确率下降也是情有可原,但是识别手写汉字对于精确度要求高,因此其实pca降维在这里并不是一件必要的事情,当资源足够时,不降维更好。
关于SVM准确率,核函数一定要选择rbf,其他两种对于非线性可分的数据集,尤其是手写汉字这种,表现的十分差。在调试参数的时候我发现惩罚系数在0.8-1.0之间准确率都没有很大的差别。
关于KNN和SVM的模型效果对比,可见KNN模型效果准确率时钟低于0.9,在手写汉字这种数据集上表现不佳。