
9.5 sklearn中的SVC
任务
提供一份糖尿病患者数据集diabetes.csv,该数据集有768个数据样本,9个特征(最后一列为目标特征数据),并且已经存入变量data。特征的具体信息如下:
| 特征名称 | 特征含义 | 取值举例 |
|---|---|---|
| feature1 | 怀孕次数 | 6 |
| feature2 | 2小时口服葡萄糖耐受实验中的血浆葡萄浓度 | 148 |
| feature3 | 舒张压 (mm Hg) | 72 |
| feature4 | 三头肌皮褶厚度(mm) | 35 |
| feature5 | 2小时血清胰岛素浓度 (mu U/ml) | 0 |
| feature6 | 体重指数(weight in kg/(height in m)^2) | 33.6 |
| feature7 | 糖尿病谱系功能(Diabetes pedigree function) | 0.627 |
| feature8 | 年龄 | 50 |
| class | 是否患有糖尿病 | 1:阳性;0:阴性 |
- 请先将数据进行标准化,然后使用sklearn中的svm.SVC支持向量分类器,构建支持向量机模型(所有参数使用默认参数),对测试集进行预测,将预测结果存为pred_y,并对模型进行评价。
预期结果
待补全代码
1 | import pandas as pd |
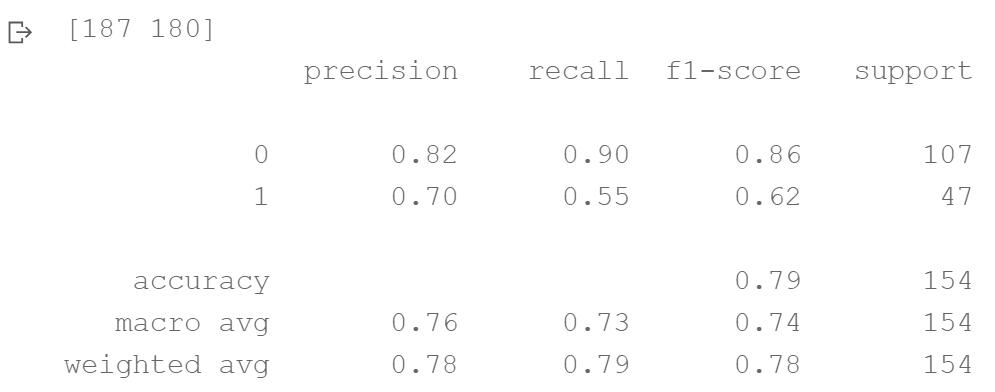
[187 180]
precision recall f1-score support
0 0.82 0.90 0.86 107
1 0.70 0.55 0.62 47
accuracy 0.79 154
macro avg 0.76 0.73 0.74 154
weighted avg 0.78 0.79 0.78 154
9.6 惩罚系数寻优
任务
- 提供一份糖尿病患者数据集diabetes.csv,该数据集有768个数据样本,9个特征(最后一列为目标特征数据),并且已经存入变量data。特征的具体信息如下:
| 特征名称 | 特征含义 | 取值举例 |
|---|---|---|
| feature1 | 怀孕次数 | 6 |
| feature2 | 2小时口服葡萄糖耐受实验中的血浆葡萄浓度 | 148 |
| feature3 | 舒张压 (mm Hg) | 72 |
| feature4 | 三头肌皮褶厚度(mm) | 35 |
| feature5 | 2小时血清胰岛素浓度 (mu U/ml) | 0 |
| feature6 | 体重指数(weight in kg/(height in m)^2) | 33.6 |
| feature7 | 糖尿病谱系功能(Diabetes pedigree function) | 0.627 |
| feature8 | 年龄 | 50 |
| class | 是否患有糖尿病 | 1:阳性;0:阴性 |
- 假设现在已经有使用sklearn中的svm.SVC训练得到的模型clf,并且所有参数为默认
- 请新建一个svm.SVC实例clf_new,并设置惩罚系数C=0.3,
- 请利用该支持向量分类器对测试集进行预测,将预测结果存为pred_y,并比较两个模型的预测效果
预期结果
待补全代码
1 | import pandas as pd |
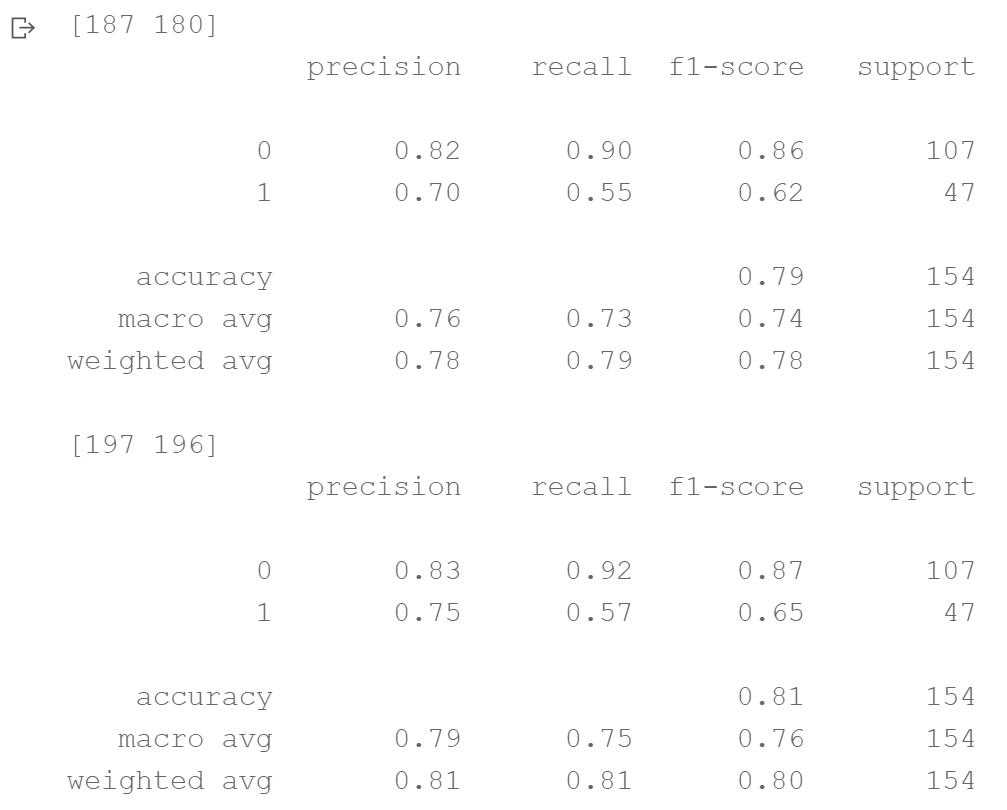
[187 180]
precision recall f1-score support
0 0.82 0.90 0.86 107
1 0.70 0.55 0.62 47
accuracy 0.79 154
macro avg 0.76 0.73 0.74 154
weighted avg 0.78 0.79 0.78 154
[197 196]
precision recall f1-score support
0 0.83 0.92 0.87 107
1 0.75 0.57 0.65 47
accuracy 0.81 154
macro avg 0.79 0.75 0.76 154
weighted avg 0.81 0.81 0.80 154
9.7 设置核函数
任务
在支持向量分类器中,核函数对其性能有直接的影响。已知径向基函数 RBF 及核矩阵元素为:
$K(\boldsymbol{x}_i, \boldsymbol{x}_j)=\exp(-\gamma|\boldsymbol{x}_i-\boldsymbol{x}_j|^2)$
$=\exp (\gamma\cdot(2\boldsymbol{x}_i^{\text{T}} \boldsymbol{x}_j- \boldsymbol{x}_i^{\text{T}}\boldsymbol{x}_i - \boldsymbol{x}_j^{\text{T}}\boldsymbol{x}j))$
,且对于核矩阵K,有$K{ij}=K(\boldsymbol{x}_i, \boldsymbol{x}_j)$
请自定义函数实现径向基函数 rbf_kernel,要求输入参数为两个矩阵 X、Y,以及 gamma
请利用以上核函数,并结合糖尿病患者数据集 diabetes.csv,计算训练数据的核矩阵,并存为 rbf_matrix
请利用训练集的 train_X 和 train_y 训练得到支持向量分类器 clf,并预测测试数据 test_X 的标签,存为 pred_y,最后评价模型效果
提示:
先计算各自的 Gram 矩阵,然后再将该矩阵扩展成
使用 np.diag 提取对角线元素,使用 np.tile 将列表扩展成一个矩阵
预期结果
待完善代码
1 | import numpy as np |
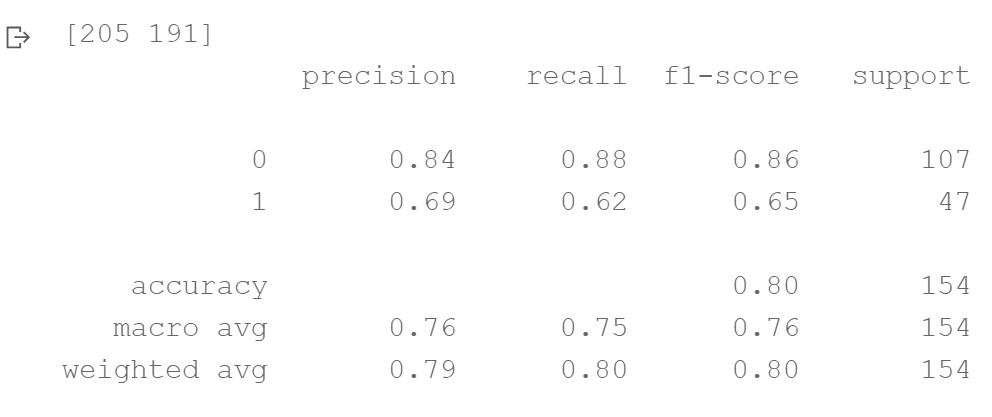
[205 191]
precision recall f1-score support
0 0.84 0.88 0.86 107
1 0.69 0.62 0.65 47
accuracy 0.80 154
macro avg 0.76 0.75 0.76 154
weighted avg 0.79 0.80 0.80 154