4.3-4.4 完整K-Means算法的实现及聚类结果评价
任务
补全完整的K-Means算法代码
在数据集data.csv上评价 K-Means 算法的聚类结果
绘出质心与所属样本
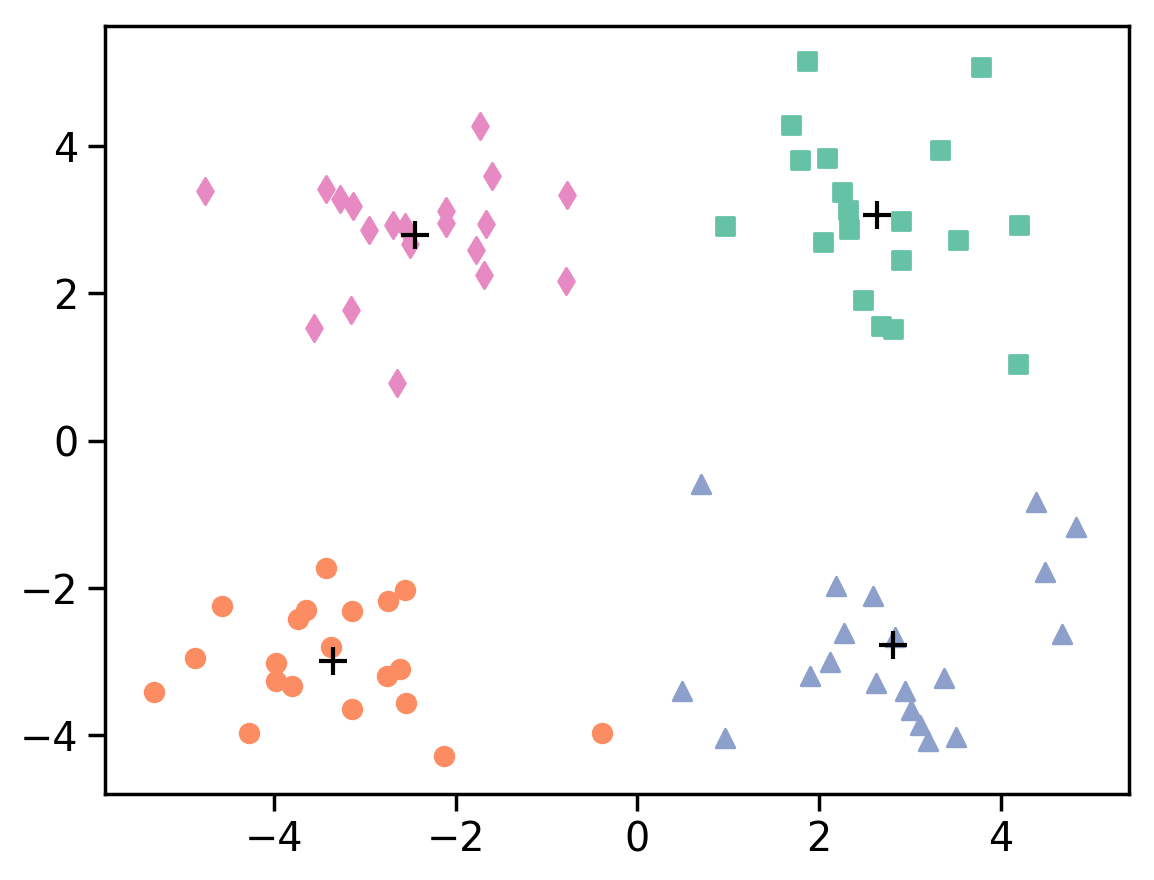
预期实验结果
待补全代码
代码1:kMeans 聚类代码实现
1 | from numpy import * |
代码2:展示kMeans聚类结果(已实现)
1 | import matplotlib.pyplot as plt |
代码3:加载数据,调用上述函数,评价聚类结果
1 | import pandas as pd |
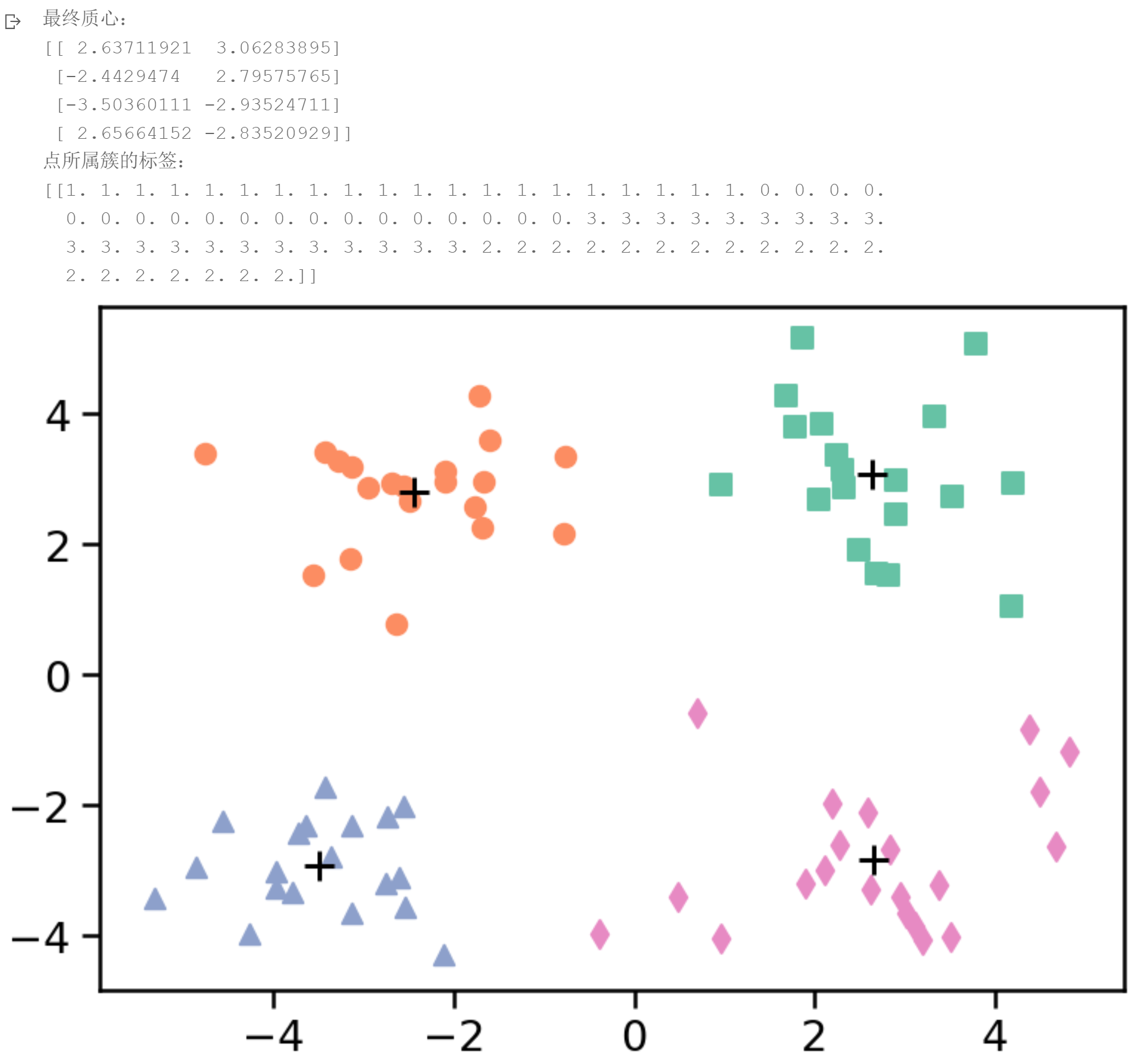
最终质心:
[[ 2.65664152 -2.83520929]
[-2.4429474 2.79575765]
[ 2.63711921 3.06283895]
[-3.50360111 -2.93524711]]
点所属簇的标签:
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 2. 2. 2. 2.
2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3.
3. 3. 3. 3. 3. 3. 3.]
4.5 sklearn中的kMeans
任务
- 调用sklearn中提供的kMeans算法
- 在数据集data.csv上评价 K-Means 算法的聚类结果
- 绘出质心与所属样本
- 对比分析与自己实验的kmeans聚类的实验结果的差异
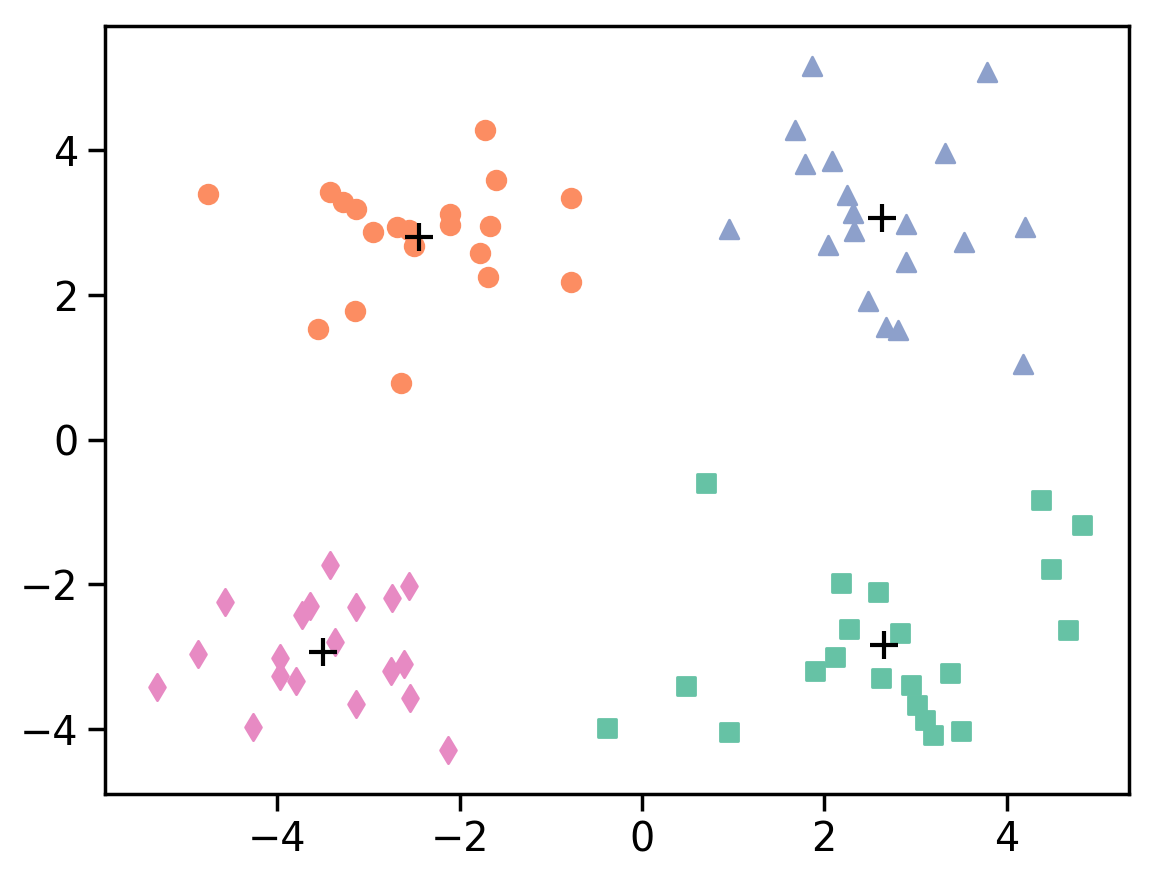
预期实验结果
待补全代码
1 | # 导入 sklearn中的KMeans工具包 |
加载数据,调用上述函数,评价聚类结果
1 | # 加载数据 |
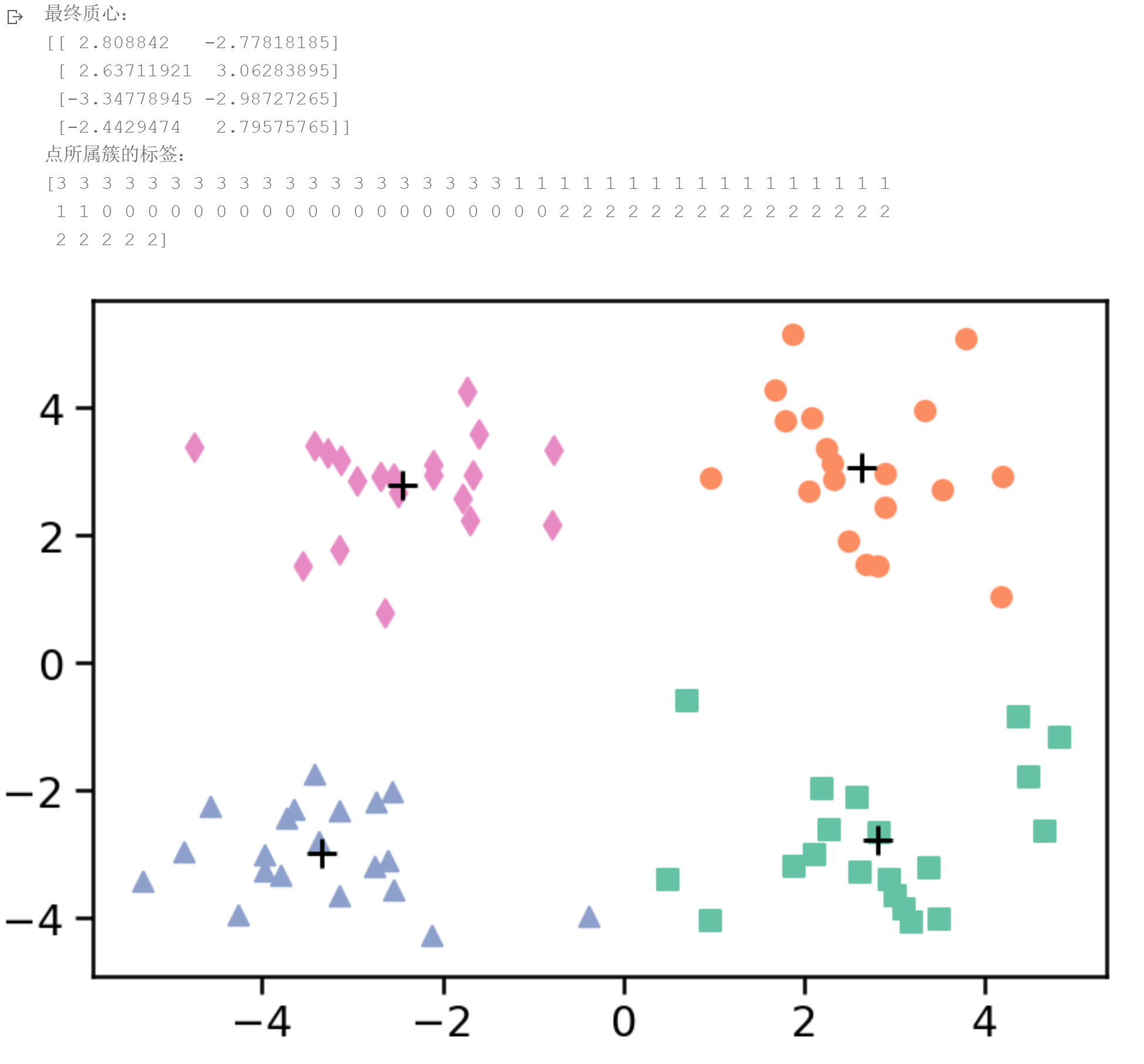
最终质心:
[[ 2.63711921 3.06283895]
[-3.34778945 -2.98727265]
[ 2.808842 -2.77818185]
[-2.4429474 2.79575765]]
点所属簇的标签:
[3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1]