
11.5 完整AdaBoost的实现
任务
已知基于单层决策树的 AdaBoost 算法的伪代码如下:
初始化所有参数,其中样本权重都为 $\frac{1}{n}$
迭代次数
i<itermax:调用
buildStump()函数得到最佳的单层决策树将该最佳单层决策树存储到单层决策树数组中
根据当前单层决策树的错误率 $\varepsilon_i$,并根据该错误率计算 $\alpha_i$
- 更新样本的权重向量 D
更新累积预测值,并计算前 i 个弱分类器集成得到的错误率
如果该错误率等于 0.0,则退出循环
其中第 t 轮训练中:
$\alpha_t = \dfrac{1}{2}\log (\dfrac{1 - \varepsilon_t}{\varepsilon_t})$
$w_i^{t + 1} = \dfrac{w_i^te^{- \alpha_ty_ih_t(\boldsymbol{x}_i)}}{Z_t}$
其中 $Z_t$ 为归一化因子
- 假设现在已经实现了基于加权输入值进行决策的最佳单层决策树生成函数
buildStump() - 请补全完整的 AdaBoost 训练函数
adaBoostTrainDS() - 请使用
adaBoostTrainDS()根据简单数据datMat,classLabels训练(迭代数为10)得到一个元模型weak_clfs
预期结果

前序代码:stumpClassify() 和 buildStump()
1 | def stumpClassify(dataMatrix, dimen, threshVal, threshIneq): |
1 | def buildStump(dataArr,classLabels,D): |
待完善代码
1 | from numpy import mat, zeros, ones, multiply, exp, sign, inf, log |
total error: 0.2
total error: 0.2
total error: 0.0
{'dim': 1, 'thresh': 0.36, 'ineq': 'gt', 'alpha': 0.9729550745276566}
11.7 sklearn中的AdaBoost
任务
给定一个二分类任务,数据集为描述马疝病的数据集,任务目标为预测患有马疝病的马是否能够存活。现已经把数据集分为训练集 train_data、train_label和测试集 test_data、 test_label。其中 train_data 包含 299 个数据样本,21 个特征;test_data 包含 67 个数据样本,21 个特征,数据集的标签取值为 1(存活)和 -1(死亡);
- 请使用
sklearn.ensemble中的AdaBoostClassifier,构建 AdaBoost 模型,完成该分类任务; - 请尝试使用不同的超参数,以使得最终模型对于测试集的准确率大于等于
0.75
预期结果
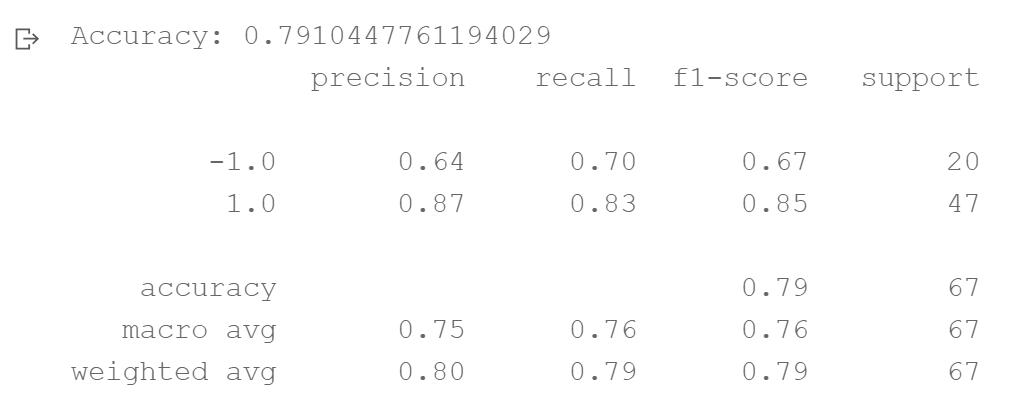
基础代码:加载数据
1 | #数据预处理 |
待完善代码
1 | from sklearn.metrics import classification_report, accuracy_score |
Accuracy: 0.8059701492537313
precision recall f1-score support
-1.0 0.65 0.75 0.70 20
1.0 0.89 0.83 0.86 47
accuracy 0.81 67
macro avg 0.77 0.79 0.78 67
weighted avg 0.82 0.81 0.81 67