
机器学习数据预处理基础
1.1 One-Hot编码
任务介绍
使用Pandas中的value_counts()函数,查看data中的特征User continent的取值类型, 并打印输出的内容;
使用pandas中的get_dummies()函数对data中的特征User continent进行One-Hot编码,参数prefix为User continent_;
将编码后的结果保存在encode_uc中,并输出变量的前5行内容。
预期实验结果

实验代码;
1 | import pandas as pd |
North America 295
Europe 118
Oceania 41
Asia 36
Africa 7
South America 7
Name: User continent, dtype: int64
User continent_Africa User continent_Asia User continent_Europe \
0 0 0 0
1 0 0 0
2 0 0 0
3 0 0 1
4 0 0 0
User continent_North America User continent_Oceania \
0 1 0
1 1 0
2 1 0
3 0 0
4 1 0
User continent_South America
0 0
1 0
2 0
3 0
4 0
1.2 缺失值填补
任务介绍
- 使用pandas中的value_counts()函数打印输出data中的特征Traveler type的取值统计信息, 并查看其是否含有缺失值;
- 如果存在缺失值,将特征Traveler type在其他样本中取值频数最多的值保存在变量freq_v中,并使用freq_v进行缺失值填充;
- 再次打印输出特征Traveler type的取值统计信息。
预期实验结果

实验代码:
1 | import pandas as pd |
Couples 214
Families 110
Friends 82
Business 74
Solo 21
NaN 3
Name: Traveler type, dtype: int64
缺失值填充完之后:
Couples 217
Families 110
Friends 82
Business 74
Solo 21
Name: Traveler type, dtype: int64
1.3 特征标准化
任务1
- 使用sklearn中preprocessing模块下的StandardScaler()函数对data的特征Score进行Z-score标准化;
- 将特征取值的均值保存在变量score_mean中,并打印;
- 将特征取值的方差保存在变量score_var中,并打印。
实验代码:
1 | import pandas as pd |
4.793343852349882e-16
1.0000000000000002
array([[ 0.87149149],
[-1.11598231],
[ 0.87149149],
[-0.12224541],
[-0.12224541]])
任务2:
- 自定义函数min_max()实现MinMax标准化,输入参数data为要进行标准化的数据,输出为标准化后的数据。
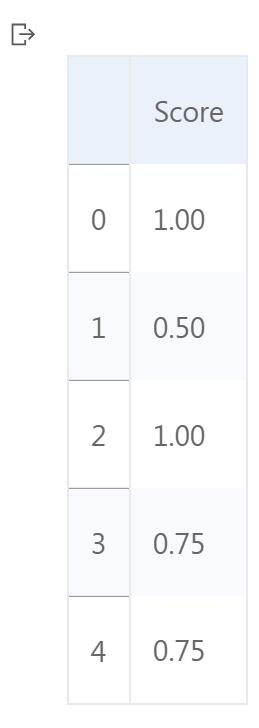
- 使自定义的min_max()函数对data的特征Score进行MinMax标准化,输出结果保存在score_transformed中,并打印变量的前5行内容
预期结果
代码:
1 | import pandas as pd |
0 1.00
1 0.50
2 1.00
3 0.75
4 0.75
Name: Score, dtype: float64
任务3:
- 自定义logistic()函数,输入参数为要进行标准化的数据,输出结果为经过标准化后的数据;
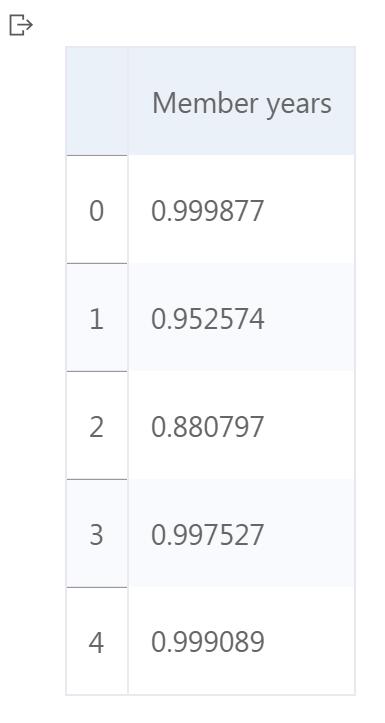
- 使用自定义函数对data的特征Member years进行Logsitic标准化,结果保存在member_transformed中,并输出变量的前5行内容。
预期结果:
代码
1 | import pandas as pd |
0 0.999877
1 0.952574
2 0.880797
3 0.997527
4 0.999089
Name: Member years, dtype: float64
1.4 特征离散化
任务
- 使用Pandas的qcut()函数对data中的特征Member years进行等频离散化,结果保存在bins中;
- 使用pd.value_counts()函数统计categorical对象bins的取值信息。
预期结果
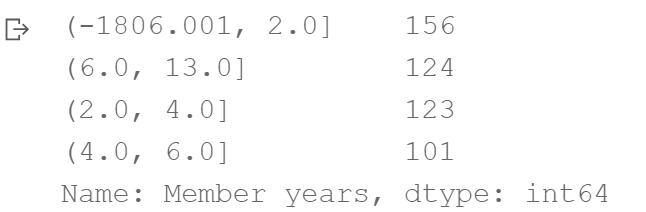
实验代码:
1 | import pandas as pd |
(-1806.001, 2.0] 156
(6.0, 13.0] 124
(2.0, 4.0] 123
(4.0, 6.0] 101
Name: Member years, dtype: int64
1.5离群值检测
任务
- 使用拉依达准则对data的特征Member years进行离群值检测;
- 如果存在离群值,输出离群值的个数outlier_num,并将包含离群值的数据记录保存在变量outeliers中,并打印变量内容。
预期结果

补全代码:
1 | import pandas as pd |
User country USA
User continent North America
Member years -1806
Traveler type Solo
Hotel name Treasure Island- TI Hotel & Casino
Hotel stars 4
Nr. rooms 2884
Score 5
Name: 75, dtype: object