
10.2 分支节点的选择方法
任务
现有一个数据集 weekend.txt,目标是预测一个人周末是否出行,所有特征均为二元特征,取值为 0 或 1。其中“status”(目标特征)表示用户的周末是否出行,1 表示出行,0 表示不出行,“marriageStatus”表示申请人是否已婚、“hasChild”表示申请人是否有小孩、“hasAppointment”表示申请人是否有约、“weather”表示天气是否晴朗;
已知信息熵和信息增益的公式为:
$\text{Entropy}(v_i)=-\sum_{i=1}^{n}P(v_i) \cdot log_2P(v_i)$
$InfoGain=Entropy(C)-\sum_{i=1}^{n}\frac{N(v_i)}{N} \cdot Entropy({C}v_i)$
请自定义函数 cal_entropy(data, feature_name)计算以某特征进行划分后的熵。输入参数 data 为 DataFrame,feature_name 为目标特征的名称;
请根据 cal_entropy() 函数计算决策树分支之前的信息熵,保存为 data_entropy;
请自定义函数 cal_infoGain 计算的信息增益,并分别计算 weekend.txt 中各个特征的信息增益,保存为列表 infogains,并依照信息增益度量的方式选择分支节点 best_feature。
预期结果

待完善代码
1 | import numpy as np |
信息增益列表: [0.0076, 0.0076, 0.0322, 0.0868]
最优的分支节点名称: weather
10.3 常见的决策树算法
任务
现在有一份有关商品销量的数据集product.csv,数据集的离散型特征信息如下:
| 特征名称 | 取值说明 |
|---|---|
| 天气 | 1:天气好;0:天气坏 |
| 是否周末 | 1:是;0:不是 |
| 是否有促销 | 1:有促销;0:没有促销 |
| 销量 | 1:销量高;0:销量低 |
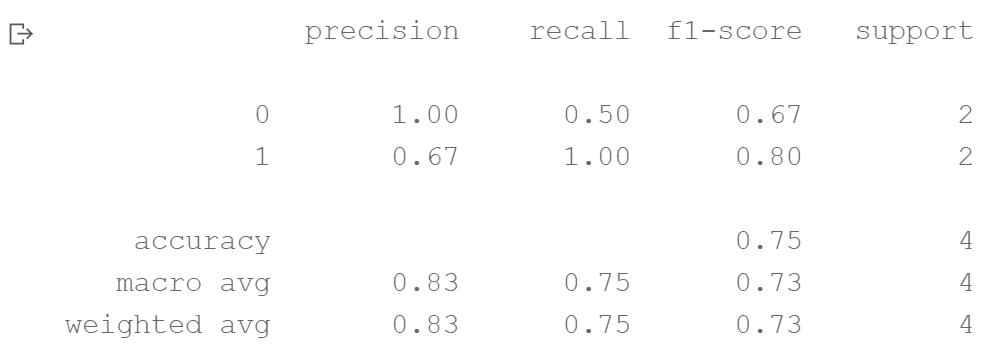
- 请根据提供的商品销量数据集 data,使用 sklearn 中的 DecisionTreeClassifier()函数构建决策树模型,模型选择分支节点的度量方式为信息熵
- 根据模型对 test_X 进行预测,将预测结果存为 pred_y
预期结果
待实现代码
1 | import pandas as pd |
precision recall f1-score support
0 1.00 0.50 0.67 2
1 0.67 1.00 0.80 2
accuracy 0.75 4
macro avg 0.83 0.75 0.73 4
weighted avg 0.83 0.75 0.73 4